Corrector: TinyCorrect v0.1-rc3 - [spaces tables pangu autocorrect epw]
Author: LucasXu lucas.xuyq.work@outlook.com
Revisor: Taotieren
Date: 2022/09/06
Project: RISC-V Linux 内核剖析
Sponsor: PLCT Lab, ISCAS
RISC-V 性能实测,以平头哥 C906 为例
前言
在上一篇文章中,我们简要概述了 Linux 下 benchmark 工具。本文将以平头哥 C906 为例,介绍如何在真实硬件上进行性能测试。
测试环境
硬件环境
| 硬件参数 | note |
|---|---|
| RISC-V 64 CPU | D1-H (C906), 1.0GHZ,接下来会用于测试 |
| X86_64 CPU | Intel Core i7-4770HQ,接下来用于 UnixBench 和 Matrix 的测试基准频率 2.2 GHZ,测试时全核稳定在 3.2GHZ. |
| X86_64 CPU | Intel Core i5-8500,用于 microbench 的测试基准频率 3.0GHZ,测试时睿频至 4.10GHZ |
| RAM | DDR3 512MB,接下来会用于测试 |
| ROM | Nor Flash 128MB,接下来会用于测试 |
| Network | 100Mb |
| Audio | 3.5mm CTIA |
| Button | fel 1 + LRADC OK1 |
| DEBUG | UART + ADB USB |
| POWER | USB Type-C 5V-2A |
| PCB 板层 | 6 层板 |
软件环境
- Debian 11,Linux kernel version: 5.4
交叉编译工具链
riscv64-linux-gnu-gcc(GCC) 11.2.0
测试方法以及工具介绍
测试工具
- 泰晓科技制作的
microbench,基于指令集的性能评测 - 我自己编写的大规模矩阵计算程序,涉及到大规模整数和浮点数计算,可以与 X86_64 平台机器做个对比进行参考,主要可用于测试单核心整数以及浮点数性能
UnixBench
工具介绍与移植
大规模矩阵计算程序
使用 C/C++ 重新改写之前一段 MATLAB 矩阵计算代码,矩阵库使用 Eigen-3.4.0 数学库进行矩阵运算。
代码如下:
#include <iostream>
#include <Eigen/Dense>
#include <random>
#include <ctime>
#include <cmath>
#include <vector>
#define EIGEN_USE_BLAS
#define PI 3.141592654
using namespace Eigen;
using namespace std;
int sign(double x)
{
if (x > 0)
return 1;
else if (x == 0)
return 0;
else
return -1;
}
double max(double a, double b)
{
if (a > b)
return a;
else
return b;
}
double max(MatrixXd x)
{
double max = x(0, 0);
for (int i = 0; i < x.rows(); i++)
{
for (int j = 0; j < x.cols(); j++)
{
if (x(i, j) > max)
{
max = x(i, j);
}
}
}
return max;
}
MatrixXd sign(MatrixXd x)
{
MatrixXd y(x.rows(), x.cols());
for (int i = 0; i < x.rows(); i++)
{
for (int j = 0; j < x.cols(); j++)
{
y(i, j) = sign(x(i, j));
}
}
return y;
}
MatrixXd proxlasso(MatrixXd x, double mu, double tk, int max_step)
{
// 创建 matrix Y 并且初始化
MatrixXd Y = MatrixXd::Zero(x.rows(), x.cols());
// matlab 语句:y = sign(x).*max(abs(x) - tk*mu, 0);
for (int i = 0; i < x.rows(); i++)
{
for (int j = 0; j < x.cols(); j++)
{
Y(i, j) = sign(x(i, j)) * max(abs(x(i, j)) - tk * mu, 0);
}
}
return Y;
}
MatrixXd eig(MatrixXd A)
{
// 求矩阵 A 的特征值
EigenSolver<MatrixXd> es(A);
MatrixXd eigenvalues = es.eigenvalues().real();
return eigenvalues;
}
MatrixXd randomMatrix(int rows, int cols)
{
srand(time(NULL));
cout << "开始生成随机数矩阵" << endl;
// 采用二重 for 循环给矩阵内容赋上随机数值
MatrixXd A;
A.resize(rows, cols);
for (int i = 0; i < rows; i++)
{
for (int j = 0; j < cols; j++)
{
double tmp = rand() % 1000000;
double tmp2 = tmp / 1000000.0;
int sign = rand() % 2;
if (sign == 0)
{
A(i, j) = tmp2;
}
else
{
A(i, j) = -tmp2;
}
}
}
cout << "随机数矩阵生成完毕" << endl;
return A;
}
double generateGaussianNoise(double mean, double sigma)
{
// 生成非 0 正态分布,只返回非零值
std::random_device rd;
std::mt19937 gen(rd());
std::normal_distribution<> d(mean, sigma);
if (d(gen) == 0.0)
{
return generateGaussianNoise(mean, sigma);
}
else
{
return d(gen);
}
}
MatrixXd sprandnMatrix(int m, int n, int density)
{
// 创建一个随机的 m×n 稀疏矩阵,在区间 [0,1] 中 density 有大约 density*m*n 个正态分布的非零项。
MatrixXd A;
A.resize(m, n);
for (int i = 0; i < m; i++)
{
for (int j = 0; j < n; j++)
{
A(i, j) = 0;
}
}
int nonzero = 97;
int count = 0;
// 生成 nonezero 个正态分布的非零项
cout << "开始生成稀疏矩阵" << endl;
while (count < nonzero)
{
int i = rand() % m;
int j = rand() % n;
if (A(i, j) == 0)
{
int sign = rand() % 2;
if (sign == 0)
{
A(i, j) = generateGaussianNoise(0, 1);
count++;
}
else
{
A(i, j) = -generateGaussianNoise(0, 1);
count++;
}
}
}
cout << "稀疏矩阵生成完毕" << endl;
return A;
}
int main()
{
clock_t start, end;
start = clock();
cout << "Start time is: " << start << endl;
int max_step = 500;
double r = 0.1;
double mu = 0.001;
int m = 512;
int n = 1024;
// 生成随机矩阵
MatrixXd A = randomMatrix(m, n);
// 生成稀疏正态分布随机矩阵(n,1),在区间 [0,1] 中 r 有大约 r*n*1 个正态分布的非零项
MatrixXd u = sprandnMatrix(n, 1, r);
// MatrixXd u = MatrixXd::Random(n, 1);
MatrixXd b = A * u;
double threshold = 0.0001;
// 准备工作完毕
// 求 A transpose * A 的特征值
MatrixXd eigenvalues = eig(A.transpose() * A);
// 求 A transpose * A 这一超大矩阵行列式
double det = (A.transpose() * A).determinant();
double tk = 1.0 / max(eig(A.transpose() * A));
int k = 0;
MatrixXd gradg = MatrixXd::Zero(1024, max_step);
MatrixXd x = MatrixXd::Zero(1024, max_step);
// 取 x 的第一列
MatrixXd f = MatrixXd::Zero(1, max_step);
f(0) = mu * x.col(0).lpNorm<1>() + 0.5 * ((A * x.col(0) - b).lpNorm<2>() * (A * x.col(0) - b).lpNorm<2>());
MatrixXd err = MatrixXd::Zero(1, max_step);
while (1)
{
gradg.col(k) = A.transpose() * (A * x.col(k) - b);
x.col(k + 1) = proxlasso((x.col(k) - tk * gradg.col(k)), mu, tk, max_step);
f(k + 1) = mu * x.col(k + 1).lpNorm<1>() + 0.5 * (A * x.col(k + 1) - b).lpNorm<2>() * (A * x.col(k + 1) - b).lpNorm<2>();
err(k) = abs((f(k + 1) - f(k)) / f(k));
if (err(k) <= threshold || k == max_step - 2)
{
break;
}
k++;
}
cout << "求得最小的函数值为:" << f(k) << endl;
cout << "迭代次数为:" << k << endl;
end = clock();
cout << "End time is: " << end << endl;
cout << "Time consumption is: " << (end - start) / CLOCKS_PER_SEC << endl;
return 0;
}
microbench
microbench 详细介绍可以详见之前的文章,这里就不再赘述。引用仓库中对 RV64 平台的移植说明如下,可以看到,microbench 的移植过程并不复杂,只需要修改一些路径即可。
make clean
make ARCH=riscv64 clean
make ARCH=riscv64
UnixBench
UnixBench 是一个用于测试 Unix 系统性能的工具,它可以测试 CPU、内存、磁盘、文件系统、网络等方面的性能。UnixBench 的移植过程也比较简单,只需要修改一下 Makefile 即可。修改后的 Makefile 如下:
##############################################################################
# UnixBench v5.1.3
# Based on The BYTE UNIX Benchmarks - Release 3
# Module: Makefile SID: 3.9 5/15/91 19:30:15
#
##############################################################################
# Bug reports, patches, comments, suggestions should be sent to:
# David C Niemi <niemi@tux.org>
#
# Original Contacts at Byte Magazine:
# Ben Smith or Tom Yager at BYTE Magazine
# bensmith@bytepb.byte.com tyager@bytepb.byte.com
#
##############################################################################
# Modification Log: 7/28/89 cleaned out workload files
# 4/17/90 added routines for installing from shar mess
# 7/23/90 added compile for dhrystone version 2.1
# (this is not part of Run file. still use old)
# removed HZ from everything but dhry.
# HZ is read from the environment, if not
# there, you must define it in this file
# 10/30/90 moved new dhrystone into standard set
# new pgms (dhry included) run for a specified
# time rather than specified number of loops
# 4/5/91 cleaned out files not needed for
# release 3 -- added release 3 files -ben
# 10/22/97 added compiler options for strict ANSI C
# checking for gcc and DEC's cc on
# Digital Unix 4.x (kahn@zk3.dec.com)
# 09/26/07 changes for UnixBench 5.0
# 09/30/07 adding ubgears, GRAPHIC_TESTS switch
# 10/14/07 adding large.txt
# 01/13/11 added support for parallel compilation
# 01/07/16 [refer to version control commit messages and
# cease using two-digit years in date formats]
##############################################################################
##############################################################################
# CONFIGURATION
##############################################################################
SHELL = /bin/sh
# GRAPHIC TESTS: Uncomment the definition of "GRAPHIC_TESTS" to enable
# the building of the graphics benchmarks. This will require the
# X11 libraries on your system. (e.g. libX11-devel mesa-libGL-devel)
#
# Comment the line out to disable these tests.
# GRAPHIC_TESTS = defined
# Set "GL_LIBS" to the libraries needed to link a GL program.
GL_LIBS = -lGL -lXext -lX11
# COMPILER CONFIGURATION: Set "CC" to the name of the compiler to use
# to build the binary benchmarks. You should also set "$cCompiler" in the
# Run script to the name of the compiler you want to test.
CC=riscv64-linux-gnu-gcc
# OPTIMISATION SETTINGS:
# Use gcc option if defined UB_GCC_OPTIONS via "Environment variable" or "Command-line arguments".
ifdef UB_GCC_OPTIONS
OPTON = $(UB_GCC_OPTIONS)
else
## Very generic
#OPTON = -O
## For Linux 486/Pentium, GCC 2.7.x and 2.8.x
#OPTON = -O2 -fomit-frame-pointer -fforce-addr -fforce-mem -ffast-math \
# -m486 -malign-loops=2 -malign-jumps=2 -malign-functions=2
## For Linux, GCC previous to 2.7.0
#OPTON = -O2 -fomit-frame-pointer -fforce-addr -fforce-mem -ffast-math -m486
#OPTON = -O2 -fomit-frame-pointer -fforce-addr -fforce-mem -ffast-math \
# -m386 -malign-loops=1 -malign-jumps=1 -malign-functions=1
## For Solaris 2, or general-purpose GCC 2.7.x
#OPTON = -O2 -fomit-frame-pointer -fforce-addr -ffast-math -Wall
## For Digital Unix v4.x, with DEC cc v5.x
#OPTON = -O4
#CFLAGS = -DTIME -std1 -verbose -w0
## gcc optimization flags
## (-ffast-math) disables strict IEEE or ISO rules/specifications for math funcs
OPTON = -O3 -ffast-math
## OS detection. Comment out if gmake syntax not supported by other 'make'.
OSNAME:=$(shell uname -s)
ARCH := $(shell uname -p)
ifeq ($(OSNAME),Linux)
# Not all CPU architectures support "-march" or "-march=native".
# - Supported : x86, x86_64, ARM, AARCH64, etc..
# - Not Supported: RISC-V, IBM Power, etc...
-march = rv64imaf
endif
ifeq ($(OSNAME),Darwin)
# (adjust flags or comment out this section for older versions of XCode or OS X)
# (-mmacosx-versin-min= requires at least that version of SDK be installed)
ifneq ($(ARCH),$(filter $(ARCH),ppc64 ppc64le))
OPTON += -march=native -mmacosx-version-min=10.10
else
OPTON += -mcpu=native
endif
#http://stackoverflow.com/questions/9840207/how-to-use-avx-pclmulqdq-on-mac-os-x-lion/19342603#19342603
CFLAGS += -Wa,-q
endif
endif
## generic gcc CFLAGS. -DTIME must be included.
CFLAGS += -Wall -pedantic $(OPTON) -I $(SRCDIR) -DTIME
##############################################################################
# END CONFIGURATION
##############################################################################
# local directories
PROGDIR = ./pgms
SRCDIR = ./src
TESTDIR = ./testdir
RESULTDIR = ./results
TMPDIR = ./tmp
# other directories
INCLDIR = /usr/include
LIBDIR = /lib
SCRIPTS = unixbench.logo multi.sh tst.sh index.base
SOURCES = arith.c big.c context1.c \
dummy.c execl.c \
fstime.c hanoi.c \
pipe.c spawn.c \
syscall.c looper.c timeit.c time-polling.c \
dhry_1.c dhry_2.c dhry.h whets.c ubgears.c
TESTS = sort.src cctest.c dc.dat large.txt
ifneq (,$(GRAPHIC_TESTS))
GRAPHIC_BINS = $(PROGDIR)/ubgears
else
GRAPHIC_BINS =
endif
# Program binaries.
BINS = $(PROGDIR)/arithoh $(PROGDIR)/register $(PROGDIR)/short \
$(PROGDIR)/int $(PROGDIR)/long $(PROGDIR)/float $(PROGDIR)/double \
$(PROGDIR)/hanoi $(PROGDIR)/syscall $(PROGDIR)/context1 \
$(PROGDIR)/pipe $(PROGDIR)/spawn $(PROGDIR)/execl \
$(PROGDIR)/dhry2 $(PROGDIR)/dhry2reg $(PROGDIR)/looper \
$(PROGDIR)/fstime $(PROGDIR)/whetstone-double $(GRAPHIC_BINS)
## These compile only on some platforms...
# $(PROGDIR)/poll $(PROGDIR)/poll2 $(PROGDIR)/select
# Required non-binary files.
REQD = $(BINS) $(PROGDIR)/unixbench.logo \
$(PROGDIR)/multi.sh $(PROGDIR)/tst.sh $(PROGDIR)/index.base \
$(PROGDIR)/gfx-x11 \
$(TESTDIR)/sort.src $(TESTDIR)/cctest.c $(TESTDIR)/dc.dat \
$(TESTDIR)/large.txt
# ######################### the big ALL ############################
all:
## Ick!!! What is this about??? How about let's not chmod everything bogusly.
# @chmod 744 * $(SRCDIR)/* $(PROGDIR)/* $(TESTDIR)/* $(DOCDIR)/*
$(MAKE) distr
$(MAKE) programs
# ####################### a check for Run ######################
check: $(REQD)
$(MAKE) all
# ##############################################################
# distribute the files out to subdirectories if they are in this one
distr:
@echo "Checking distribution of files"
# scripts
@if test ! -d $(PROGDIR) \
; then \
mkdir $(PROGDIR) \
; mv $(SCRIPTS) $(PROGDIR) \
; else \
echo "$(PROGDIR) exists" \
; fi
# C sources
@if test ! -d $(SRCDIR) \
; then \
mkdir $(SRCDIR) \
; mv $(SOURCES) $(SRCDIR) \
; else \
echo "$(SRCDIR) exists" \
; fi
# test data
@if test ! -d $(TESTDIR) \
; then \
mkdir $(TESTDIR) \
; mv $(TESTS) $(TESTDIR) \
; else \
echo "$(TESTDIR) exists" \
; fi
# temporary work directory
@if test ! -d $(TMPDIR) \
; then \
mkdir $(TMPDIR) \
; else \
echo "$(TMPDIR) exists" \
; fi
# directory for results
@if test ! -d $(RESULTDIR) \
; then \
mkdir $(RESULTDIR) \
; else \
echo "$(RESULTDIR) exists" \
; fi
.PHONY: all check distr programs run clean spotless
programs: $(BINS)
# (use $< to link only the first dependency, instead of $^,
# since the programs matching this pattern have only
# one input file, and others are #include "xxx.c"
# within the first. (not condoning, just documenting))
# (dependencies could be generated by modern compilers,
# but let's not assume modern compilers are present)
$(PROGDIR)/%:
$(CC) -o $@ $(CFLAGS) $< $(LDFLAGS)
# Individual programs
# Sometimes the same source file is compiled in different ways.
# This limits the 'make' patterns that can usefully be applied.
$(PROGDIR)/arithoh: $(SRCDIR)/arith.c $(SRCDIR)/timeit.c
$(PROGDIR)/arithoh: CFLAGS += -Darithoh
$(PROGDIR)/register: $(SRCDIR)/arith.c $(SRCDIR)/timeit.c
$(PROGDIR)/register: CFLAGS += -Ddatum='register int'
$(PROGDIR)/short: $(SRCDIR)/arith.c $(SRCDIR)/timeit.c
$(PROGDIR)/short: CFLAGS += -Ddatum=short
$(PROGDIR)/int: $(SRCDIR)/arith.c $(SRCDIR)/timeit.c
$(PROGDIR)/int: CFLAGS += -Ddatum=int
$(PROGDIR)/long: $(SRCDIR)/arith.c $(SRCDIR)/timeit.c
$(PROGDIR)/long: CFLAGS += -Ddatum=long
$(PROGDIR)/float: $(SRCDIR)/arith.c $(SRCDIR)/timeit.c
$(PROGDIR)/float: CFLAGS += -Ddatum=float
$(PROGDIR)/double: $(SRCDIR)/arith.c $(SRCDIR)/timeit.c
$(PROGDIR)/double: CFLAGS += -Ddatum=double
$(PROGDIR)/poll: $(SRCDIR)/time-polling.c
$(PROGDIR)/poll: CFLAGS += -DUNIXBENCH -DHAS_POLL
$(PROGDIR)/poll2: $(SRCDIR)/time-polling.c
$(PROGDIR)/poll2: CFLAGS += -DUNIXBENCH -DHAS_POLL2
$(PROGDIR)/select: $(SRCDIR)/time-polling.c
$(PROGDIR)/select: CFLAGS += -DUNIXBENCH -DHAS_SELECT
$(PROGDIR)/whetstone-double: $(SRCDIR)/whets.c
$(PROGDIR)/whetstone-double: CFLAGS += -DDP -DGTODay -DUNIXBENCH
$(PROGDIR)/whetstone-double: LDFLAGS += -lm
$(PROGDIR)/pipe: $(SRCDIR)/pipe.c $(SRCDIR)/timeit.c
$(PROGDIR)/execl: $(SRCDIR)/execl.c $(SRCDIR)/big.c
$(PROGDIR)/spawn: $(SRCDIR)/spawn.c $(SRCDIR)/timeit.c
$(PROGDIR)/hanoi: $(SRCDIR)/hanoi.c $(SRCDIR)/timeit.c
$(PROGDIR)/fstime: $(SRCDIR)/fstime.c
$(PROGDIR)/syscall: $(SRCDIR)/syscall.c $(SRCDIR)/timeit.c
$(PROGDIR)/context1: $(SRCDIR)/context1.c $(SRCDIR)/timeit.c
$(PROGDIR)/looper: $(SRCDIR)/looper.c $(SRCDIR)/timeit.c
$(PROGDIR)/ubgears: $(SRCDIR)/ubgears.c
$(PROGDIR)/ubgears: LDFLAGS += -lm $(GL_LIBS)
$(PROGDIR)/dhry2: CFLAGS += -DHZ=${HZ}
$(PROGDIR)/dhry2: $(SRCDIR)/dhry_1.c $(SRCDIR)/dhry_2.c \
$(SRCDIR)/dhry.h $(SRCDIR)/timeit.c
$(CC) -o $@ ${CFLAGS} $(SRCDIR)/dhry_1.c $(SRCDIR)/dhry_2.c
$(PROGDIR)/dhry2reg: CFLAGS += -DHZ=${HZ} -DREG=register
$(PROGDIR)/dhry2reg: $(SRCDIR)/dhry_1.c $(SRCDIR)/dhry_2.c \
$(SRCDIR)/dhry.h $(SRCDIR)/timeit.c
$(CC) -o $@ ${CFLAGS} $(SRCDIR)/dhry_1.c $(SRCDIR)/dhry_2.c
# Run the benchmarks and create the reports
run:
sh ./Run
clean:
$(RM) $(BINS) core *~ */*~
spotless: clean
$(RM) $(RESULTDIR)/* $(TMPDIR)/*
## END ##
测试方法
microbench和UnixBench在 X86_64 平台进行移植与交叉编译,并在 RV64 平台上面进行测试,查看测试所得的分数。- 大规模矩阵计算程序在 X86_64 平台上进行到 RV64 平台的交叉编译与移植,测试程序在 RV64 平台上运行,查看运行时间。
测试结果
microbench 测试结果
BM_nop 3.08 ns 2.99 ns 233889145
BM_ub 3.10 ns 2.99 ns 233893313
BM_bnez 12.4 ns 12.0 ns 58507883
BM_beqz 12.3 ns 12.0 ns 58468358
BM_load_bnez 12.2 ns 12.0 ns 58395094
BM_load_beqz 12.1 ns 12.0 ns 58380949
BM_cache_miss_load_bnez 12.2 ns 5.99 ns 116951654
BM_cache_miss_load_beqz 12.4 ns 5.99 ns 116876961
BM_branch_miss_load_bnez 8.56 ns 4.00 ns 175331742
BM_branch_miss_load_beqz 8.15 ns 3.99 ns 175418777
BM_cache_branch_miss_load_bnez 9.79 ns 4.82 ns 141039686
BM_cache_branch_miss_load_beqz 10.3 ns 4.96 ns 127321246
BM_inc 10.2 ns 9.97 ns 70122305
BM_dec 11.2 ns 11.0 ns 63613111
BM_mul 12.2 ns 12.0 ns 58461644
BM_div 11.1 ns 11.0 ns 63466231
BM_float_inc 18.5 ns 18.0 ns 39003335
BM_float_dec 18.5 ns 18.0 ns 39007247
BM_float_mul 18.5 ns 18.0 ns 38973395
BM_float_div 33.9 ns 32.9 ns 21276946
BM_and 11.2 ns 11.0 ns 63815846
BM_or 11.4 ns 11.0 ns 63767351
BM_not 11.3 ns 11.0 ns 63709582
BM_bits_and 11.3 ns 11.0 ns 63730270
BM_bits_or 12.2 ns 12.0 ns 58254510
BM_bits_nor 12.2 ns 12.0 ns 58446391
BM_bits_not 12.7 ns 12.0 ns 58380200
BM_bits_rshift 11.3 ns 11.0 ns 63750367
BM_bits_lshift 11.4 ns 11.0 ns 63743425
BM_for_loop 24.7 ns 24.0 ns 29241522
BM_while_loop 24.6 ns 23.9 ns 29267222
BM_do_while_loop 24.8 ns 23.9 ns 29262257
BM_bubble_sort 339 ns 328 ns 2160002
BM_std_sort 197 ns 192 ns 3683400
BM_calculate_pi 5182 ns 5073 ns 137929
BM_factorial 108 ns 106 ns 6612491
| benchmark | time_rv64/ns | cpu_rv64/ns | iterations_rv64 |
|---|---|---|---|
| BM_nop | 3.08 | 2.99 | 233889145 |
| BM_ub | 3.1 | 2.99 | 233893313 |
| BM_bnez | 12.4 | 12 | 58507883 |
| BM_beqz | 12.3 | 12 | 58468358 |
| BM_load_bnez | 12.2 | 12 | 58395094 |
| BM_load_beqz | 12.1 | 12 | 58380949 |
| BM_cache_miss_load_bnez | 12.2 | 5.99 | 116951654 |
| BM_cache_miss_load_beqz | 12.4 | 5.99 | 116876961 |
| BM_branch_miss_load_bnez | 8.56 | 4 | 175331742 |
| BM_branch_miss_load_beqz | 8.15 | 3.99 | 175418777 |
| BM_cache_branch_miss_load_bnez | 9.79 | 4.82 | 141039686 |
| BM_cache_branch_miss_load_beqz | 10.3 | 4.96 | 127321246 |
| BM_inc | 10.2 | 9.97 | 70122305 |
| BM_dec | 11.2 | 11 | 63613111 |
| BM_mul | 12.2 | 12 | 58461644 |
| BM_div | 11.1 | 11 | 63466231 |
| BM_float_inc | 18.5 | 18 | 39003335 |
| BM_float_dec | 18.5 | 18 | 39007247 |
| BM_float_mul | 18.5 | 18 | 38973395 |
| BM_float_div | 33.9 | 32.9 | 21276946 |
| BM_and | 11.2 | 11 | 63815846 |
| BM_or | 11.4 | 11 | 63767351 |
| BM_not | 11.3 | 11 | 63709582 |
| BM_bits_and | 11.3 | 11 | 63730270 |
| BM_bits_or | 12.2 | 12 | 58254510 |
| BM_bits_nor | 12.2 | 12 | 58446391 |
| BM_bits_not | 12.7 | 12 | 58380200 |
| BM_bits_rshift | 11.3 | 11 | 63750367 |
| BM_bits_lshift | 11.4 | 11 | 63743425 |
| BM_for_loop | 24.7 | 24 | 29241522 |
| BM_while_loop | 24.6 | 23.9 | 29267222 |
| BM_do_while_loop | 24.8 | 23.9 | 29262257 |
| BM_bubble_sort | 339 | 328 | 2160002 |
| BM_std_sort | 197 | 192 | 3683400 |
| BM_calculate_pi | 5182 | 5073 | 137929 |
| BM_factorial | 108 | 106 | 6612491 |
UnixBench 测试结果
------unixbench----
------------------------------------------------------------------------
Benchmark Run: Wed Sep 07 2022 14:56:22 - 15:24:31
1 CPU in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 3001049.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 1047.8 MWIPS (10.0 s, 7 samples)
Execl Throughput 334.6 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 42369.6 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 11763.5 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 120604.7 KBps (30.0 s, 2 samples)
Pipe Throughput 208931.1 lps (10.0 s, 7 samples)
Pipe-based Context Switching 30214.6 lps (10.0 s, 7 samples)
Process Creation 790.2 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 719.0 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 92.6 lpm (60.2 s, 2 samples)
System Call Overhead 380766.8 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 3001049.4 257.2
Double-Precision Whetstone 55.0 1047.8 190.5
Execl Throughput 43.0 334.6 77.8
File Copy 1024 bufsize 2000 maxblocks 3960.0 42369.6 107.0
File Copy 256 bufsize 500 maxblocks 1655.0 11763.5 71.1
File Copy 4096 bufsize 8000 maxblocks 5800.0 120604.7 207.9
Pipe Throughput 12440.0 208931.1 168.0
Pipe-based Context Switching 4000.0 30214.6 75.5
Process Creation 126.0 790.2 62.7
Shell Scripts (1 concurrent) 42.4 719.0 169.6
Shell Scripts (8 concurrent) 6.0 92.6 154.4
System Call Overhead 15000.0 380766.8 253.8
========
System Benchmarks Index Score 133.4
| name | baseline | rv64_result | unit | comment |
|---|---|---|---|---|
| Dhrystone 2 using register variables | 106700 | 3001049.4 | lps | (10.0 s, 7 samples) |
| Double-Precision Whetstone | 55 | 1047.8 | MWIPS | (10.0 s, 7 samples) |
| Execl Throughput | 43 | 334.6 | lps | (29.9 s, 2 samples) |
| File Copy 1024 bufsize 2000 maxblocks | 3960 | 42369.6 | KBps | (30.0 s, 2 samples) |
| File Copy 256 bufsize 500 maxblocks | 1655 | 11763.5 | KBps | (30.0 s, 2 samples) |
| File Copy 4096 bufsize 8000 maxblocks | 5800 | 120604.7 | KBps | (30.0 s, 2 samples) |
| Pipe Throughput | 12440 | 208931.1 | lps | (10.0 s, 7 samples) |
| Pipe-based Context Switching | 4000 | 30214.6 | lps | (10.0 s, 7 samples) |
| Process Creation | 126 | 790.2 | lps | (30.0 s, 2 samples) |
| Shell Scripts (1 concurrent) | 42.4 | 719 | lpm | (60.0 s, 2 samples) |
| Shell Scripts (8 concurrent) | 6 | 92.6 | lpm | (60.0 s, 2 samples) |
| System Call Overhead | 15000 | 380766.8 | lps | (10.0 s, 7 samples) |
大规模矩阵计算程序测试结果
Start time is: 6262
开始生成随机数矩阵
随机数矩阵生成完毕
开始生成稀疏矩阵
稀疏矩阵生成完毕
求得最小的函数值为:0.142769
迭代次数为:162
End time is: 785892387
Time consumption is: 785
与现阶段 X86_64 平台机器进行性能对比
与 Intel Core i7-4770HQ 和 Intel Core i5-8500 进行性能对比
与 i5-8500 测试 microbench 性能对比图表见下
| benchmark | time_X86_64/ns | time_rv64/ns | cpu_X86_64/ns | cpu_rv64/ns | iterations_X86_64 | iterations_rv64 | ratio_time | ratio_cpu | ratio_iterations |
|---|---|---|---|---|---|---|---|---|---|
| BM_nop | 0.248 | 3.08 | 0.248 | 2.99 | 1000000000 | 233889145 | 12.4193548 | 12.0564516 | 4.27552976 |
| BM_ub | 0.879 | 3.1 | 0.879 | 2.99 | 794629566 | 233893313 | 3.52673493 | 3.40159272 | 3.397401815 |
| BM_bnez | 0.99 | 12.4 | 0.99 | 12 | 708983810 | 58507883 | 12.5252525 | 12.1212121 | 12.11774848 |
| BM_beqz | 0.991 | 12.3 | 0.991 | 12 | 706511735 | 58468358 | 12.4117053 | 12.1089808 | 12.08365959 |
| BM_load_bnez | 0.799 | 12.2 | 0.799 | 12 | 906538755 | 58395094 | 15.2690864 | 15.0187735 | 15.52422803 |
| BM_load_beqz | 1.1 | 12.1 | 1.1 | 12 | 632241417 | 58380949 | 11 | 10.9090909 | 10.82958444 |
| BM_cache_miss_load_bnez | 2.2 | 12.2 | 2.2 | 5.99 | 333106358 | 116951654 | 5.54545455 | 2.72272727 | 2.848239821 |
| BM_cache_miss_load_beqz | 2.34 | 12.4 | 2.34 | 5.99 | 294563456 | 116876961 | 5.2991453 | 2.55982906 | 2.520286748 |
| BM_branch_miss_load_bnez | 1.91 | 8.56 | 1.91 | 4 | 363788231 | 175331742 | 4.48167539 | 2.09424084 | 2.074856651 |
| BM_branch_miss_load_beqz | 1.8 | 8.15 | 1.8 | 3.99 | 409687271 | 175418777 | 4.52777778 | 2.21666667 | 2.335481287 |
| BM_cache_branch_miss_load_bnez | 3.75 | 9.79 | 3.75 | 4.82 | 190417310 | 141039686 | 2.61066667 | 1.28533333 | 1.350097376 |
| BM_cache_branch_miss_load_beqz | 3.57 | 10.3 | 3.57 | 4.96 | 199812939 | 127321246 | 2.88515406 | 1.38935574 | 1.569360537 |
| BM_inc | 0.495 | 10.2 | 0.495 | 9.97 | 1000000000 | 70122305 | 20.6060606 | 20.1414141 | 14.26079762 |
| BM_dec | 0.618 | 11.2 | 0.618 | 11 | 1000000000 | 63613111 | 18.1229773 | 17.7993528 | 15.72002979 |
| BM_mul | 0.558 | 12.2 | 0.558 | 12 | 1000000000 | 58461644 | 21.8637993 | 21.5053763 | 17.10523228 |
| BM_div | 0.805 | 11.1 | 0.805 | 11 | 871044955 | 63466231 | 13.7888199 | 13.6645963 | 13.72454203 |
| BM_float_inc | 0.997 | 18.5 | 0.997 | 18 | 710661226 | 39003335 | 18.555667 | 18.0541625 | 18.22052463 |
| BM_float_dec | 0.992 | 18.5 | 0.992 | 18 | 696412695 | 39007247 | 18.6491935 | 18.1451613 | 17.85341824 |
| BM_float_mul | 0.801 | 18.5 | 0.801 | 18 | 870941987 | 38973395 | 23.0961298 | 22.4719101 | 22.34709055 |
| BM_float_div | 0.909 | 33.9 | 0.909 | 32.9 | 764747492 | 21276946 | 37.2937294 | 36.1936194 | 35.94254044 |
| BM_and | 0.617 | 11.2 | 0.617 | 11 | 1000000000 | 63815846 | 18.1523501 | 17.828201 | 15.67008921 |
| BM_or | 0.618 | 11.4 | 0.618 | 11 | 1000000000 | 63767351 | 18.4466019 | 17.7993528 | 15.6820063 |
| BM_not | 0.619 | 11.3 | 0.619 | 11 | 1000000000 | 63709582 | 18.2552504 | 17.7705977 | 15.69622604 |
| BM_bits_and | 0.562 | 11.3 | 0.562 | 11 | 1000000000 | 63730270 | 20.1067616 | 19.5729537 | 15.69113076 |
| BM_bits_or | 0.559 | 12.2 | 0.559 | 12 | 1000000000 | 58254510 | 21.8246869 | 21.4669052 | 17.16605289 |
| BM_bits_nor | 0.556 | 12.2 | 0.556 | 12 | 1000000000 | 58446391 | 21.942446 | 21.5827338 | 17.1096963 |
| BM_bits_not | 0.555 | 12.7 | 0.555 | 12 | 1000000000 | 58380200 | 22.8828829 | 21.6216216 | 17.12909514 |
| BM_bits_rshift | 0.555 | 11.3 | 0.555 | 11 | 1000000000 | 63750367 | 20.3603604 | 19.8198198 | 15.68618421 |
| BM_bits_lshift | 0.558 | 11.4 | 0.558 | 11 | 1000000000 | 63743425 | 20.4301075 | 19.7132616 | 15.68789252 |
| BM_for_loop | 3.04 | 24.7 | 3.04 | 24 | 235779692 | 29241522 | 8.125 | 7.89473684 | 8.063181253 |
| BM_while_loop | 3.25 | 24.6 | 3.25 | 23.9 | 215554143 | 29267222 | 7.56923077 | 7.35384615 | 7.365035978 |
| BM_do_while_loop | 2.98 | 24.8 | 2.98 | 23.9 | 235437929 | 29262257 | 8.32214765 | 8.02013423 | 8.045788437 |
| BM_bubble_sort | 31 | 339 | 31 | 328 | 22556145 | 2160002 | 10.9354839 | 10.5806452 | 10.44265005 |
| BM_std_sort | 9.74 | 197 | 9.74 | 192 | 72264119 | 3683400 | 20.2258727 | 19.7125257 | 19.61886274 |
| BM_calculate_pi | 127 | 5182 | 127 | 5073 | 5446257 | 137929 | 40.8031496 | 39.9448819 | 39.48594567 |
| BM_factorial | 9.15 | 108 | 9.15 | 106 | 76995221 | 6612491 | 11.8032787 | 11.5846995 | 11.6439056 |
| average | 15.4073332 | 14.6701879 | 13.23012203 |
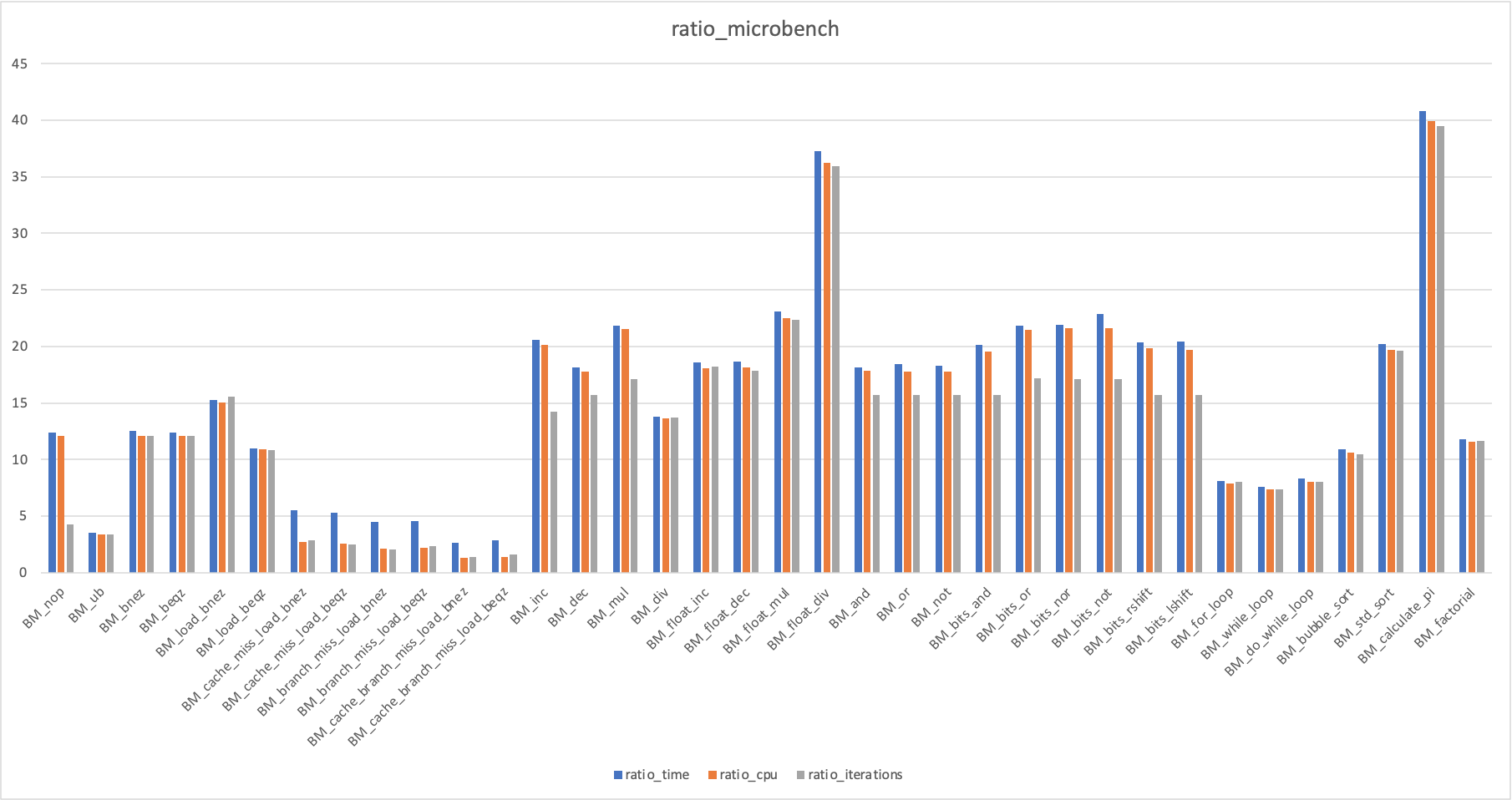
和 i7-4770HQ 对比 Unixbench
Benchmark Run: Wed Sep 07 2022 19:59:17 - 20:23:52
8 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 32343533.0 lps (10.0 s, 7 samples)
Double-Precision Whetstone 4533.0 MWIPS (10.5 s, 7 samples)
Execl Throughput 3263.5 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 635715.1 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 168269.6 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 2003899.3 KBps (30.0 s, 2 samples)
Pipe Throughput 677305.6 lps (10.0 s, 7 samples)
Pipe-based Context Switching 110291.0 lps (10.0 s, 7 samples)
Process Creation 8915.2 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 9925.1 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 2371.0 lpm (60.0 s, 2 samples)
System Call Overhead 554765.5 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 32343533.0 2771.5
Double-Precision Whetstone 55.0 4533.0 824.2
Execl Throughput 43.0 3263.5 759.0
File Copy 1024 bufsize 2000 maxblocks 3960.0 635715.1 1605.3
File Copy 256 bufsize 500 maxblocks 1655.0 168269.6 1016.7
File Copy 4096 bufsize 8000 maxblocks 5800.0 2003899.3 3455.0
Pipe Throughput 12440.0 677305.6 544.5
Pipe-based Context Switching 4000.0 110291.0 275.7
Process Creation 126.0 8915.2 707.6
Shell Scripts (1 concurrent) 42.4 9925.1 2340.8
Shell Scripts (8 concurrent) 6.0 2371.0 3951.7
System Call Overhead 15000.0 554765.5 369.8
========
System Benchmarks Index Score 1111.4
------------------------------------------------------------------------
Benchmark Run: Wed Sep 07 2022 20:23:52 - 20:48:38
8 CPUs in system; running 8 parallel copies of tests
Dhrystone 2 using register variables 107735436.2 lps (10.0 s, 7 samples)
Double-Precision Whetstone 25460.0 MWIPS (9.3 s, 7 samples)
Execl Throughput 10155.8 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 1254565.5 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 326444.0 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 3831671.6 KBps (30.0 s, 2 samples)
Pipe Throughput 2871966.9 lps (10.0 s, 7 samples)
Pipe-based Context Switching 280889.3 lps (10.0 s, 7 samples)
Process Creation 24198.2 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 24486.0 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 3283.5 lpm (60.0 s, 2 samples)
System Call Overhead 2258288.6 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 107735436.2 9231.8
Double-Precision Whetstone 55.0 25460.0 4629.1
Execl Throughput 43.0 10155.8 2361.8
File Copy 1024 bufsize 2000 maxblocks 3960.0 1254565.5 3168.1
File Copy 256 bufsize 500 maxblocks 1655.0 326444.0 1972.5
File Copy 4096 bufsize 8000 maxblocks 5800.0 3831671.6 6606.3
Pipe Throughput 12440.0 2871966.9 2308.7
Pipe-based Context Switching 4000.0 280889.3 702.2
Process Creation 126.0 24198.2 1920.5
Shell Scripts (1 concurrent) 42.4 24486.0 5775.0
Shell Scripts (8 concurrent) 6.0 3283.5 5472.5
System Call Overhead 15000.0 2258288.6 1505.5
========
System Benchmarks Index Score 3037.7
性能对比图表见下:
| name | baseline | rv64_result | X86_64_result | ratio | unit | comment |
|---|---|---|---|---|---|---|
| Dhrystone 2 using register variables | 106700 | 3001049.4 | 32343533 | 10.77740773 | lps | (10.0 s, 7 samples) |
| Double-Precision Whetstone | 55 | 1047.8 | 4533 | 4.326207291 | MWIPS | (10.0 s, 7 samples) |
| Execl Throughput | 43 | 334.6 | 3263.5 | 9.75343694 | lps | (29.9 s, 2 samples) |
| File Copy 1024 bufsize 2000 maxblocks | 3960 | 42369.6 | 635715.1 | 15.00403827 | KBps | (30.0 s, 2 samples) |
| File Copy 256 bufsize 500 maxblocks | 1655 | 11763.5 | 168269.6 | 14.3043822 | KBps | (30.0 s, 2 samples) |
| File Copy 4096 bufsize 8000 maxblocks | 5800 | 120604.7 | 2003899.3 | 16.6154329 | KBps | (30.0 s, 2 samples) |
| Pipe Throughput | 12440 | 208931.1 | 677305.6 | 3.241765348 | lps | (10.0 s, 7 samples) |
| Pipe-based Context Switching | 4000 | 30214.6 | 110291 | 3.650255175 | lps | (10.0 s, 7 samples) |
| Process Creation | 126 | 790.2 | 8915.2 | 11.28220704 | lps | (30.0 s, 2 samples) |
| Shell Scripts (1 concurrent) | 42.4 | 719 | 9925.1 | 13.80403338 | lpm | (60.0 s, 2 samples) |
| Shell Scripts (8 concurrent) | 6 | 92.6 | 2371 | 25.60475162 | lpm | (60.0 s, 2 samples) |
| System Call Overhead | 15000 | 380766.8 | 554765.5 | 1.4569692 | lps | (10.0 s, 7 samples) |
| avg | 10.81840726 |
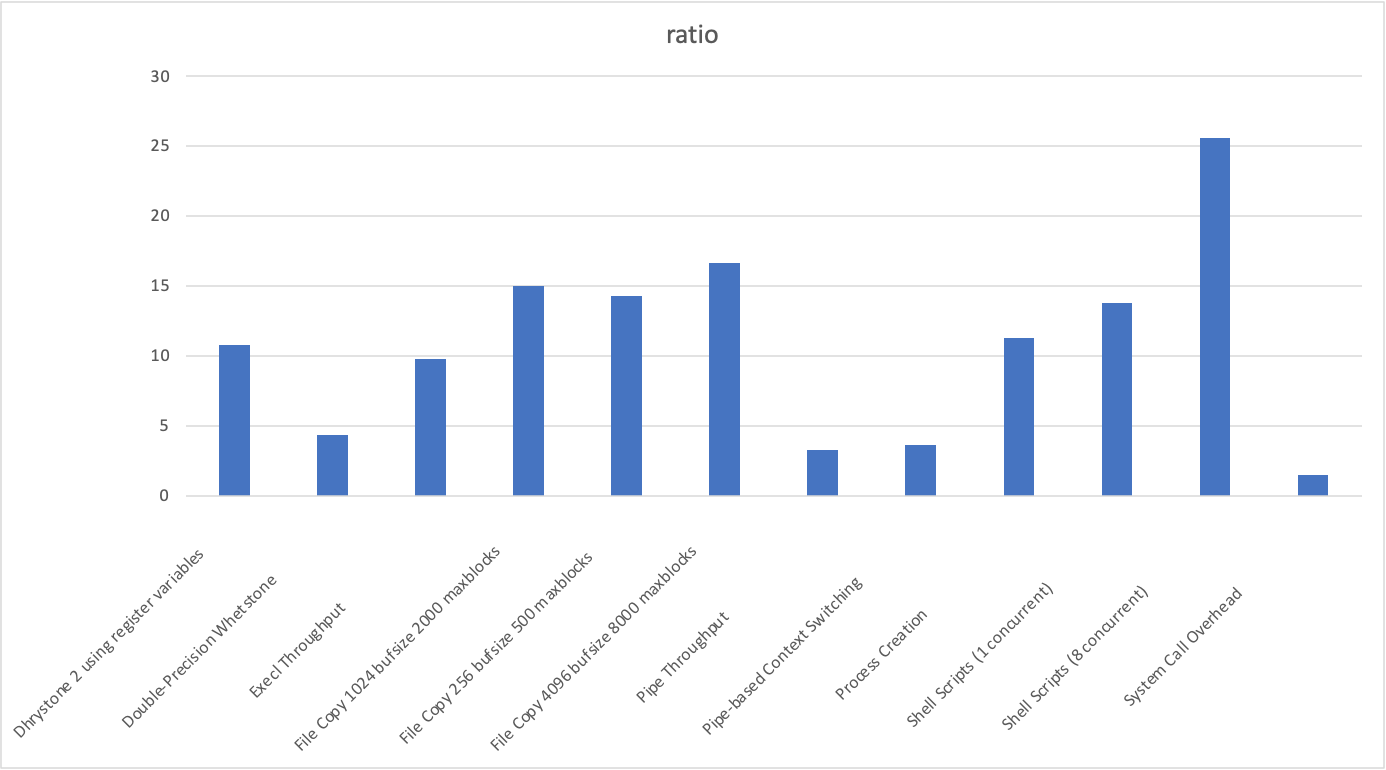
经过计算可以得出,选用的 X86_64 架构 CPU 性能大概为所选用的 rv64 架构 CPU 的 10 倍。
和 i7-4770HQ 对比大规模矩阵运算程序
Start time is: 1097
开始生成随机数矩阵
随机数矩阵生成完毕
开始生成稀疏矩阵
稀疏矩阵生成完毕
求得最小的函数值为:0.151914
迭代次数为:170
End time is: 20455667
Time consumption is: 20
与 rv64 处理器相比,耗时差距大概为 39.25 倍
总结
- 由于是第一次接触 RISC-V 开发板,之前上面搭载的的是未完全移植的 ArchLinux 系统,设备驱动还十分不完善,导致在进行移植时遇到了很多问题,比如无法使用 HDMI 接口等,这些问题都是由于设备驱动不完善导致的,后来通过移植相对完整的 Debian 系统解决了这些问题。
- 移植的 Debian 系统中没有
glibc库,导致无法使用gcc进行交叉编译,后来通过移植glibc库解决了这个问题。 - 在移植大规模矩阵计算程序时,由于原始代码编译出的程序运算量过于大,在开发板上运行时间过长(跑了三天三夜都没结束),导致无法进行测试,后来通过 O2 优化解决了这个问题。
- 由上面测试以及所得到的图表,结果显而易见,即便仅进行单核性能对比,RISC-V 平台处理器对于目前已经成熟的 X86_64 平台处理器也有着明显的性能劣势,这种性能差距不仅仅是频率所导致的,而是由于 RISC-V 平台处理器的设计和 X86_64 平台处理器的设计的差异以及两款处理器的实现工艺所导致的。该 RISC-V 芯片的基础指令性能跟对比的 X86_64 芯片性能差异较大(4-10 倍),即使换算到同等主频(2-5 倍),差异也较为明显。
- 换算至同频率后,性能对比如下:
| 测试项目 | 同频性能下对比 |
|---|---|
| microbench | i7-4770HQ 4.51 倍于 XuanTie C906 |
| UnixBench | i5-8500 2.64 倍于 XuanTie C906 |
| Matrix | i7-4700HQ 12.26 倍于 XuanTie C906 |
参考资料
上篇Welcome